TULER#
[ICJAI2017] Identifying Human Mobility via Trajectory Embeddings
1. 摘要#
理解人类的轨迹模式在许多基于位置的社交网络(Location-based Social Networks,LBSNs)应用中是一项重要任务,比如个性化推荐和基于偏好的路径规划。
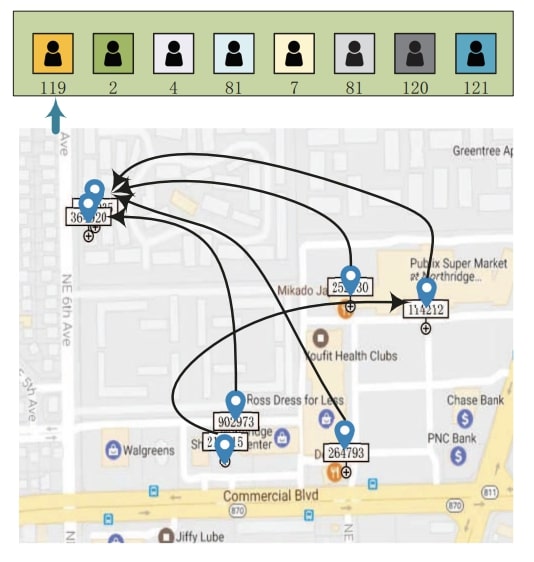
TUL(轨迹-用户链接,Trajectory-User Linking)是一种轨迹分类任务,旨在将轨迹与生成这些轨迹的用户在基于位置的社交网络(LBSNs)中进行关联。TUL任务面临两个主要挑战:(1)用户的数量(即类别的数量)远超过一般轨迹分类任务中运动模式类别的数量;(2)基于位置的轨迹序列数据通常是稀疏的。
本文提出了一种名为TULER(TUL via Embedding and RNN)的模型,这是一种基于循环神经网络(RNN)的半监督学习深度模型,其利用时空数据蕴含的信息来捕获用户的移动模式潜在语义,实验结果其在TUL任务上表现优越。
Note
TULER发表于2017年,在2017年使用基于递归神经网络(RNN)的深度学习模型来解决轨迹序列问题的研究相对较少。
2. 问题定义#
定义一条由用户\(u_i\)在一段时间间隔内产生的轨迹序列为:
其中\(l_{ij}\)(\(j \in [1,n]\))为该用户在时刻\(t_j\)采集到的位置点,一般形式为\((x_{l_{ij}},y_{l_{ij}})\)。
对于一条其所属用户未知的轨迹序列\(T_k=\{l_1,l_2,\ldots,l_m\}\), 我们称之为“未链接”的序列。假设我们有一定数量的未链接轨迹序列\(\mathcal{T}=\{T_1, \ldots,T_m\}\),这些序列是由一个集合内的用户\(\mathcal{U}=\{u_1, \dots, u_n\}(m \gg n)\)所产生, TUL任务要做的事情是将\(\mathcal{T}\)中的每一条轨迹序列,链接(分类)到\(\mathcal{U}\)中的用户上,即\(\mathcal{T} \mapsto \mathcal{U}\)。
3. TULER算法介绍#
TULER算法主要包含以下模块:
词向量嵌入模块
序列表征模块
映射分类模块
下面,我们用Gowalla数据集作为示例数据来介绍TULER算法的每个模块。
Note
关于Gowalla数据集的详细介绍和使用方法,见Open Source Dataset。
3.1. 轨迹预分割#
为了降低计算复杂度和捕获更丰富的移动模式特征,这里将原始的轨迹序列\(T_{u_i}\)划分为\(k\)个连续的子序列\(T_{u_i}^1,\ldots,T_{u_i}^k\)。具体的划分方式参考ST-RNN。
3.2. 词向量嵌入模块#
在TULER中,词向量嵌入层使用Word2Vec中的skip-gram或CBOW算法来进行预训练。使用预训练得到的Word2Vec模型,输入轨迹序列,即可得到该序列对应的词嵌入向量表示,可以作为后续序列表征模块的输入。关于Word2Vec的相关算法不在此处作详细介绍。
Tip
词向量嵌入模块在如今已经成为深度学习领域序列表征的常用做法。在训练词向量模块之前需要构建tokenizer来将轨迹序列转换为token,详细可见Tokenizer。
3.3. 序列表征模块#
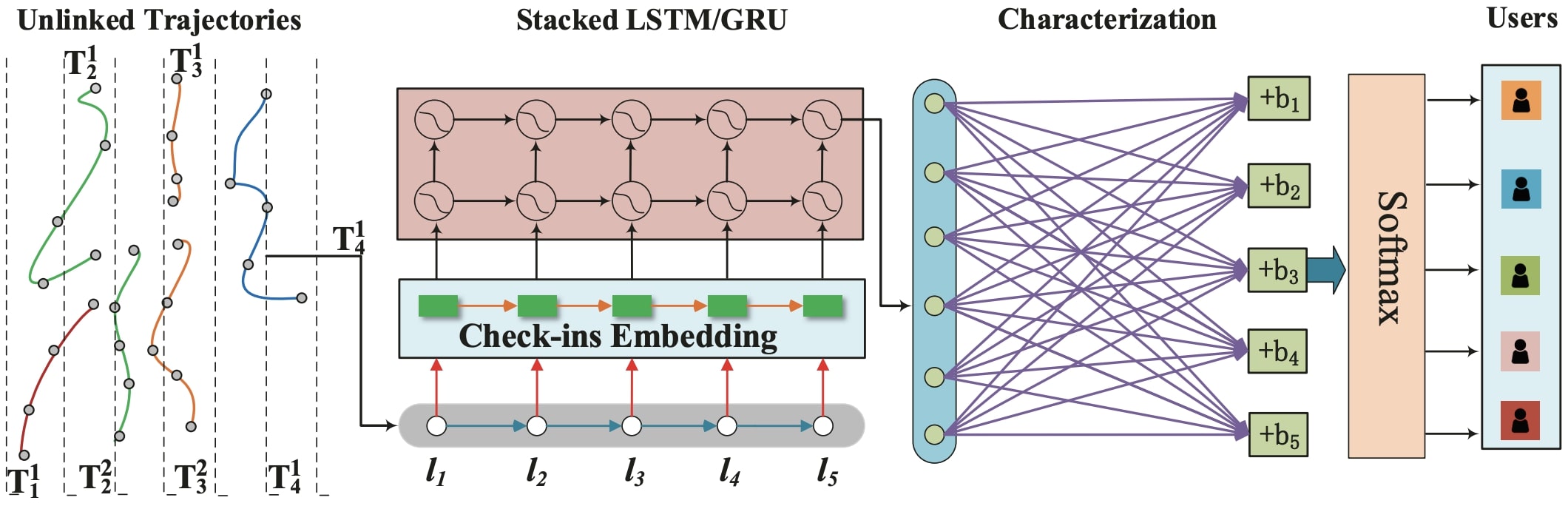
TULER模型结构如图2。对于序列数据,在TULER中使用RNN系列(LSTM、GRU)的基础组件来构建序列表征层。这里使用公式简单介绍GRU模块和LSTM模块。然后再介绍TULER在此基础上的变体。
基于LSTM的轨迹序列表征模块
对于子轨迹序列\(T=\{l_1, l_2, \ldots, l_k\}\), 应用LSTM模型进行计算:
(2)#\[ i_t = \sigma(W_i\mathbf{v}^t(l_i)+U_ih_{t-1}+V_ic_{t-1}+b_i) \](3)#\[ f_t = \sigma(W_f\mathbf{v}^t(l_i)+U_fh_{t-1}+V_fc_{t-1}+b_f) \](4)#\[ o_t = \sigma(W_o\mathbf{v}(l_i)+U_oh_{t-1}+V_oc_t+b_o) \]其中, \(i_t, f_t, o_t\)分别是输入门、遗忘门和输出门的输出, \(\mathbf{v}^t(l_i)\)是Check-in \(l_i\)的输入。\(c_t\)的更新方式如下:
(5)#\[ c_t = f_tc_{t-1} + i_t \tanh (W_c\mathbf{v}(l_i) + U_ch_{t-1} + b_c) \]最终得到该序列\(T\)的表示为(5):
(6)#\[ h_t = o_t \odot \tanh(c_t) \]基于GRU的轨迹序列表征模块
(7)#\[ h_t = (1-g_t)h_{t-1} + g_t \tilde{h}_t \](8)#\[ g_t = \sigma(W_z\mathbf{v}^t(l_i) + U_zh_{t-1}) \](9)#\[ \tilde{h}_t = \tanh(W\mathbf{v}^t(l_i)+U(s_t \odot h_{t-1})) \](10)#\[ s_t = \sigma(W_s\mathbf{v}^t(l_i) + U_sh_{t-1}) \]
3.4. 映射分类模块#
映射分类模块是由一个线性层和\(\mathrm{softmax}\)层组成,如下:
其中\(W_{u_i} \in \mathbb{R}^{|c| \times H}\),\(h_{u_i} \in \mathbb{R}^{H \times 1}\),\(b_{u_i} \in \mathbb{R}^{|c| \times 1}\),\(|c|\)即为用户集合\(\mathcal{U}\)的用户数量。
该模块的输出是\(|c|\)个类别的概率,概率最大的类别\(c_{\max}\)即为最终分类的结果。显然,对于该分类问题的优化使用交叉熵(cross entropy)作为损失函数即可。
Note
这里\(\mathrm{softmax}\)由于类别的数量过于庞大导致计算很慢,可以参考Candidate Sampling算法来解决这个问题。TrajDL后续会在TULER上支持该算法。
4. 代码示例#
我们以Notebook的形式,使用TrajDL中的API实现了TULER算法在Gowalla数据集上的训练和推理,参见Quick Start。
Tip
本文介绍了轨迹领域的任务TUL。
本文介绍了TULER算法,使用基于RNN系列的模型来做轨迹序列的表征来解决该任务。