HST-LSTM#
1. 摘要#
位置预测任务(Location Prediction)是轨迹序列分析中的一个重要研究领域。本文中,作者提出了一种改进版的HST-LSTM模型,旨在解决在弱时间约束下的用户下一位置预测问题。在此模型中,作者基于LSTM进行了改进,融入了时空相关的约束,以缓解数据稀疏性带来的挑战。此外,作者还提出了一个Encoder-Decoder层级结构的HST-LSTM模型,即HST-LSTM,在该模型中,引入了上下文位置信息表征层,这一层将用户历史访问的上下文位置信息整合到模型中,从而有效提升下一位置预测的准确性。
2. 预备知识#
2.1. 术语定义#
在介绍HST-LSTM之前,需要先介绍该论文中提出的相关术语:
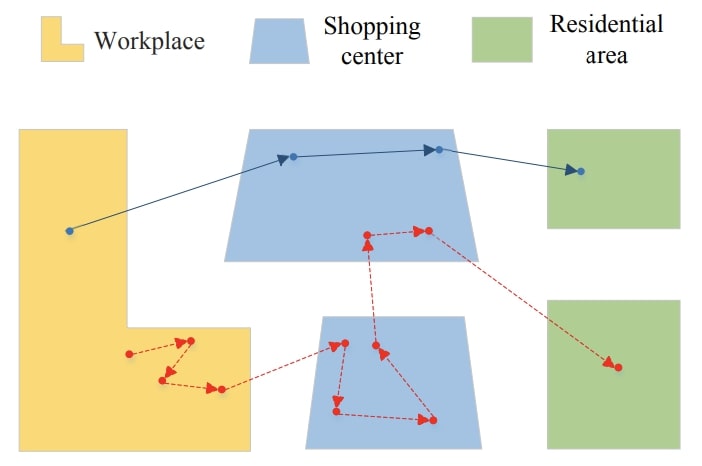
AOI (Area of Interest,感兴趣区域):指代一个地理位置上的提供相关功能的区域,比如购物商场、居民小区、公司大厦等。AOI呈现的方式是在地图上,会将某个区域使用多边形包围起来,形成一个封闭的区域,该区域即为一个AOI。
访问位置记录 (Visit Record):指代一个用户在过去的一段时间内(几周或几个月)到访过的AOI的集合。
访问会话(Visit Session):用户在特定时间段内访问过的AOI序列(比如在本文中,用自然天来分割,一个时间段就是一天)。在同一个会话里面的AOI具有较强的相关性,能够揭示用户行动模式。
访问会话序列(Visit Session Sequence):一个访问会话序列包含了一个用户连续的访问会话。一个用户历史的访问会话信息可以看成是上下文信息,可以用来帮助预测用户下一个要访问的AOI或者未来访问会话。
2.2. 符号定义#
对于上述的领域术语,现在来给出数学上的符号定义,便于后续论文的解读。
假设一个用户\(u\)在过去有\(n\)个访问会话\(\{S_1, S_2, \ldots, S_n\}\),其中一个访问会话\(S_i(i \in [1, n])\)由一个AOI序列\(\{l_1^i, l_2^i, \ldots, l_{m_i}^i\}\)构成,\(m_i\)表示访问会话\(S_i\)的长度。因此,该用户\(u\)的访问记录\(V_u\)可以表示为\(\{\ldots, l_1^i, l_2^i, \ldots, l_{m_i}^i,\ldots,l_1^n, l_2^n, \ldots, l_{m_n}^n\}\),为了简单起见,在这里定义\(V_u\)为\(\{l_1^u, l_2^u, \ldots, l_N^u\}\),其中\(N\)是用户\(u\)访问过的所有位置。
因此,在本文中位置预测任务可以定义为: 给定一个用户的\(u\)前\(j\)个访问的位置集合\(\{l_1^u, \ldots, l_j^u\}\),预测未来\(N-j\)个用户最有可能访问的位置集合\(\{l_{j+1}^u, \ldots,l_N^u\}\)。
3. HST-LSTM#
HST-LSTM的结构图如下:
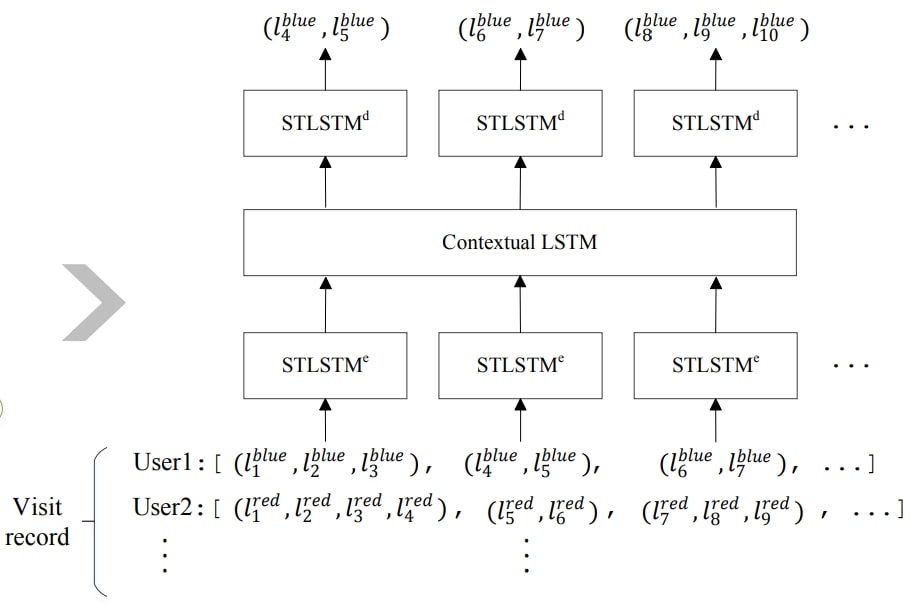
HST-LSTM是编码器-解码器架构的模型,其中复用最多的模块HST-LSTM是基于标准LSTM融入时间和空间的信息改进的,Contextual-LSTM模块将历史的访问会话进行表征,引入上下文的信息。
3.1. HST-LSTM模块#
HST-LSTM是基于标准的LSTM改进的,给定时间\(t\)时刻的输入\(l_t\),假设HST-LSTM输出的隐藏状态变量为\(h_t\),下面给出HST-LSTM的推理公式:
其中\(s,q \in \mathbb{R}^d\),为HST-LSTM中定义的空间影响因子和时间影响因子。\(s_{t-1}\)和\(q_{t-1}\)为位置\(l_{t-1}\)和位置\(l_t\)之间的空间和时间上的向量表示。\(F(\cdot)\)是一个线性加法函数,定义为如下:
其中,\(\mathbf{W}_{sk},\mathbf{W}_{qk} \in \mathbb{R}^{|c| \times d}\)是线性转换矩阵,\(|c|\)表示HST-LSTM隐藏层的维度。
此处,因为物理世界中,在两个AOI之间采集到的时间间隔和空间间隔都是连续的变量,为了能够将其作为模型的输入,需要离散化转换为token,结合向量嵌入层(embedding layer)就可以作为模型的输入。在这里,作者离散化的方式是将这些连续的间隔进行切片(slot)操作,每一片都是一个token。具体的离散化方式在下文进行介绍。
先定义一个真实世界中的时间间隔\(v_q\)和空间间隔\(v_s\),比如从一个用户从商场购物区\(AOI_1\)移动到居住小区\(AOI_2\),所花费的时间是\(v_q\),移动的距离是\(v_s\),于是为了将\(v_q\)和\(v_s\)离散化,有如下计算:
其中,\(u(v_q)\)和\(l(v_q)\)是\(v_q\)在时间切片中的上界和下界,\(u(v_s)\)和\(l(v_s)\)是距离切片中的上界和下界(可以认为是token)。\(Q \in \mathbb{R}^{N_q \times d}\)和\(S \in \mathbb{R}^{N_s \times d}\)分别是时间和空间的因子矩阵(可以认为是embedding matrix),其中\(N_q\)和\(N_s\)分别表示时间和空间上的总的切片数量(可以认为是vocabulary size)
举一个例子,假如时间切片的方式是每小时切成一片,距离切片的方式是每200米切成一片,那么用户从购物商场回到自己的居住小区,位置转移花费的时间是1.3小时,移动的距离是700米,那么\(v_q=1.3\),\(v_s=700\),\(v_q\)在时间片\([2, 3]\)之间,\(v_s\)在距离切片\([3, 4]\)之间,所以有\(u(v_q)=3, l(v_q)=2, u(v_s)=4, l(v_s)=3\)向量化的\(q\)和\(v\)。
3.2. 编码器#
接下来介绍编码器的工作原理。如上文对访问会话的介绍所言,在一个会话内的访问位置序列(AOI sequence)具有较强的相关性,给定一个用户\(u\)的访问记录\(V_u\),其包含访问会话\(\{S_1, S_2, \ldots,S_n\}\),对于\(i \in [1, n-1]\)的时间步,首先将其访问会话\(S_i = \{l_1^i, l_2^i, \ldots, l_{m_i}^i\}\)编码成向量表示:
其中,\(\mathbf{h}_0^{e,i}= \mathbf{0},j=1,\ldots,m_i,\mathbf{h}_e^i=\mathbf{h}_{m_i}^{e,i},\mathbf{h}_e^0=\mathbf{0}\)。编码器利用HST-LSTM模块,将访问会话\(S_i\)中的AOI位置序列编码成向量表示,其中\(\mathbf{W}_l\)是向量嵌入层,将AOI位置ID转换为向量表示。我们将编码器输出的一个会话的最后一个隐藏状态\(h_{m_i}^{e,i}\)作为整个访问会话\(S_i\)的向量表示,定义为\(\mathbf{h}_e^i\)。
3.3. 全局上下文编码#
在将访问会话编码成向量之后,我们得到所有访问会话的向量表示\(\{\mathbf{h}_e^0,\mathbf{h}_e^1,\ldots,\mathbf{h}_e^{n-1}\}\), 我们使用LSTM模块来编码访问会话之间的上下文向量表示,以此来捕获长周期的特征:
其中,\(h_c^0 = \mathbf{0};i=1, \ldots,n\)。在(12)的\(\mathbf{h}_c^i\)表示时间\(t\)步的全局上下文表示。
3.4. 解码器和位置预测#
对于用户\(u\),我们有起访问会话\({S_1, S_2, \ldots, S_n}\)以及上下文向量表征\(\{\mathbf{h}_c^0,\mathbf{h}_c^1,\ldots,\mathbf{h}_c^{n-1}\}\),所以解码的计算公式如下:
其中,\(l_j^i\)表示访问会话\(S_i\)中的第\(j\)个AOItoken。
我们定义\(\mathbf{h}_j^{d,i}\)是Session \(S_i\)中过去经过的\(j\)各区域的综合特征,表征这用户在时间\(j\)内的路由目的,因此,我们基于此来预测该用户的下一位置概率:
\(\mathbf{p}_j^i\)就是预测下一位置的AOI的概率,于是可以得到下一AOI最大的概率为:
3.5. 优化目标#
在下一位置预测的问题中,本质上还是对候选位置的分类任务,所以优化的目标与分类任务一样——最大似然函数:
其中\(\mathcal{N}\)表示所有的访问记录,\(l_j^i\)表示Session \(S_i\)第\(j\)个AOI,\(m_i\)表示\(S_i\)中AOI的数量。\(\theta\)表示所有的模型参数。
显然,该优化目标能够转换为交叉熵(cross entropy)的计算,在此不做赘述。
4. 代码示例#
我们以Notebook的形式,使用TrajDL实现了ST-LSTM的训练和推理,参见ST-LSTM代码实践。
Tip
本文介绍了轨迹序列领域中的位置预测任务。
本文介绍了HST-LSTM模型,其引入时空数据特征和全局上下文特征来进行特征的融合增强。